Chunking? Google’s File Search solved that. SAP’s got its own take as well.
Remember the days when building a document Q&A system meant endless experimentation with chunk sizes, overlap strategies, and embedding models? Good news: those days are over (well, mostly).
The Chunking Problem We've All Faced
If you've ever built a RAG (Retrieval-Augmented Generation) application, you know the drill:
- Upload a document
- Split it into chunks (but how big? 512 tokens? 1000 characters?)
- Should chunks overlap? By how much?
- Generate embeddings (which model? OpenAI? Google? Open-source?)
- Store them in a vector database (Pinecone? Weaviate? Build your own?)
- Hope you got it right, because changing chunk size means re-processing everything
It's tedious, error-prone, and honestly? It's not where you want to spend your time when you're just trying to build a cool AI feature.
Google's Answer: File Search
If you've been following Google's Gemini ecosystem, you might know about File Search, a managed RAG service that handles all this complexity for you:
- Upload documents (PDFs, text files, etc.)
- Google automatically chunks them intelligently
- Embeddings are generated and stored
- You just query and get relevant results
No vector database to manage. No chunking strategy debates. Just upload and query. Simple.
Plot Twist: SAP Has This Too
Here's what many developers don't know: SAP has a similar solution called the Document Grounding Service in SAP AI Core.
It works similar to Google's File Search:
- Create a collection (think: a container for your documents)
- Upload documents - SAP automatically:
- Parses your files (text, PDFs, etc.)
- Chunks them intelligently
- Generates vector embeddings
- Stores them in a managed vector store
- Search semantically - just send a query and get the most relevant chunks
- Integrate with LLMs - combine search results with any LLM for Q&A
The best part? You control nothing about the chunking, in a good way. SAP's Document Grounding Service handles paragraph detection, sentence boundaries, and optimal chunk sizing based on their research.
Why This Matters
Both services represent a shift in how we think abou approaching RAG:
Old way:
Your App → Manual Chunking Logic → Embedding API → Vector DB → Search → LLM
↑ You manage all of this complexity ↑
New way:
Your App → Managed Service API → Get Results
↑ Service handles chunking, embeddings, search ↑
You go from managing 5+ components to calling a single API. This is the serverless movement hitting the RAG space.
Seeing It In Action: Document Chat Service
Google provides an interactive File Search demo to showcase their service. To demonstrate SAP's Document Grounding Service in action, I built a similar demo application: a Document Chat Service where you can upload PDFs or text files and ask questions about them.
Implementation Note: This demo uses Document Grounding Service's Vector API, which requires you to specify the chunk size when embedding documents. Document Grounding Service also offers a Pipelines API that handles this automatically which means you don't need to configure chunk sizes, and after data is embedded, you can directly use the Retrieval API for a more streamlined experience.
What It Does
- Upload any document - drag-and-drop a PDF or text file
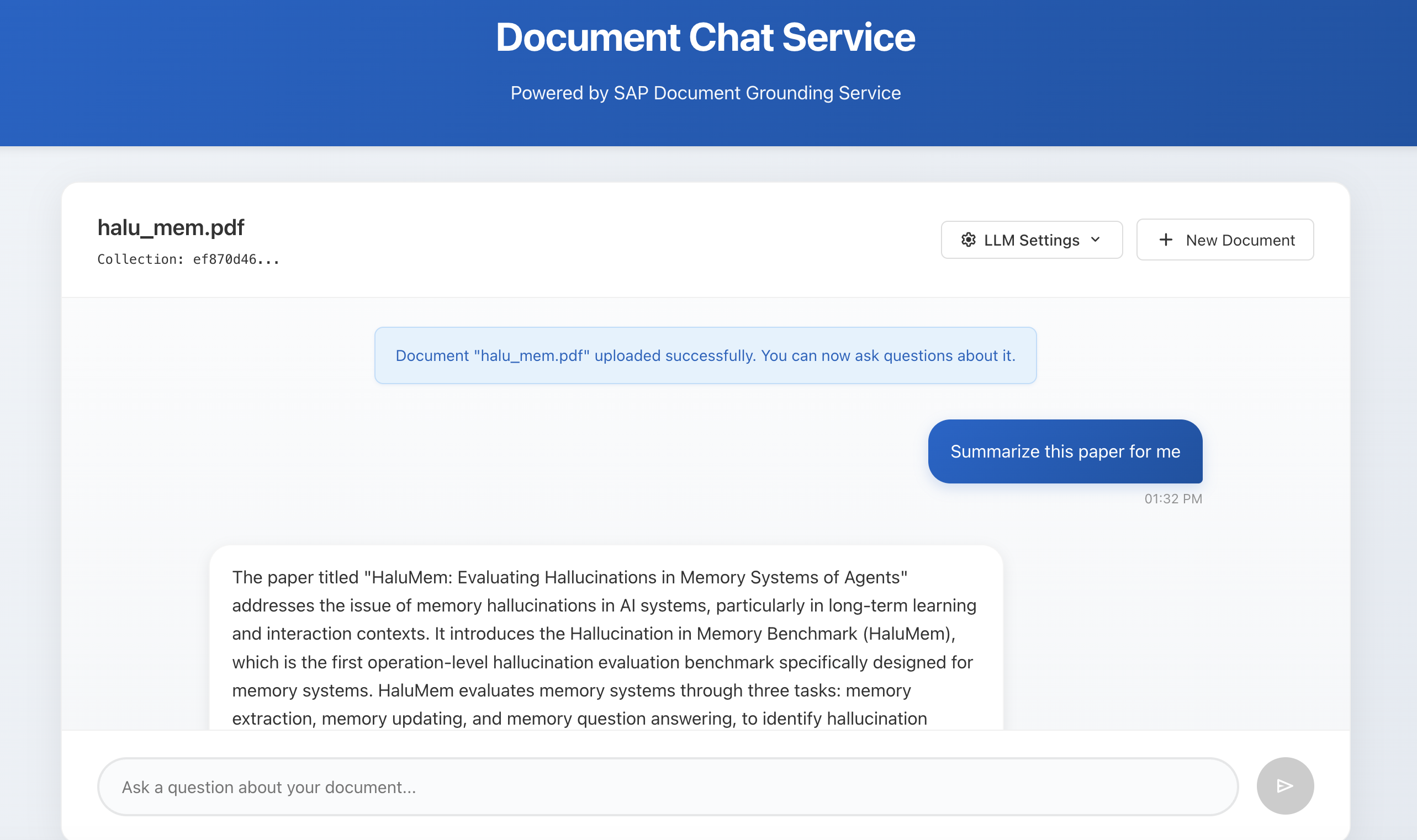
- Ask questions - natural language queries like "What are the main findings?" or "Summarize the conclusions"
- Get grounded answers - the AI responds based on actual document content, showing you which chunks informed the answer
How It Works (High Level)
Frontend (React + Vite):
- Clean, modern UI for file upload and chat
- Drag-and-drop support
- Real-time message history
- Shows source chunks with relevance scores
Backend (FastAPI + Python):
- Handles file uploads and text extraction
- Creates SAP AI Core collections
- Sends documents to Document Grounding Service
- Orchestrates semantic search + LLM responses
SAP AI Core Integration:
- Document Grounding Service (Vector API): Stores document embeddings and enables semantic search
- Generative AI Hub: Provides access to LLMs (GPT-4o, GPT-3.5-turbo, etc.)
How It Works
When you upload a document:
Your PDF → Backend extracts text → Chunked with specified size → Vector API
↓
[Embeddings generated]
[Stored in vector collection]
↓
Ready to search!
When you ask a question:
Your Query → Vector API searches the collection → Returns top 5 relevant chunks
↓
Chunks + Your Question → LLM generates answer
↓
You get the answer + see which chunks were used
What's Configurable
You control what matters for the AI behavior:
- LLM Model: Choose between GPT-4o, GPT-3.5-turbo, or other models
- Temperature: Control creativity vs. precision (0.0 = deterministic, 1.0 = creative)
- Max Chunks: How many relevant sections to include as context (default: 5)
- Max Tokens: Response length limit
This is the right level of abstraction. You control the AI behavior, not the infrastructure.
When Should You Use Managed Document Services?
Great for:
- Prototypes and MVPs (get started in minutes)
- Internal tools and dashboards
- Applications where document processing isn't your core differentiator
- Teams without deep ML/vector database expertise
- When you need reliability and don't want to manage infrastructure
Maybe not for:
- Highly specialized chunking requirements (e.g., code with syntax awareness)
- Extreme cost optimization at massive scale
- Offline/air-gapped environments
- When you need 100% control over the embedding model
For most use cases though? The managed approach wins on speed, simplicity, and maintainability.
Want to try it yourself? The complete source code, technical details, and setup instructions are available on GitHub. Clone the repo and start building your own document chat service today.
Enjoyed this post?
If this brought you value, consider buying me a coffee. It helps me keep writing.